Warren B Powell
Professor Emeritus, Princeton University
I served as Area Editor of Operations Research for eight years (1988-1996) which was a period that taught me a lot about the weaknesses of the standard way of handling papers (send paper to AE who sends it to referees, and then do what the referees say). It took me two years to realize that this approach just wasn’t working. I came up with an entirely new approach which I summarized in a memo available here. This web page is a brief summary of the core ideas.
It all begins with three principles:
- Let authors be authors
- Let editors be editors
- Let referees be referees
I explain below.
Let authors be authors
The responsibility of authors is to write, as clearly as possible, a paper that offers something new. For this reason, the author is in the best position to tell us what is new and significant in their paper.
An idea I was given by Mark Daskin (who adopted it from his colleague Phil Jones) is to include, typically in the next-to-last paragraph of the introductory section, a paragraph that begins with “This paper makes the following contributions.” The rest of this paragraph should be a list that contains what the author feels are publishable contributions. The last paragraph should give the organization of the paper.
Note that a contribution is not a list of what the paper has done. Implicit in each contribution is an implicit claim that it is original and significant. In other words, each contribution should contain a claim that may be verified by knowledgeable reviewers.
Let editors be editors
First let me emphasize: there is more to editorial work than just picking an AE or reviewers, sending it out, and then repeating whatever the referees tell you to do. When I was active in editorial work, we called these people “mailboxes.”
Given the list of contributions, the first responsibility of any editor is to read the list and then make a judgment of the form “If this claimed contribution is true, does this seem to be of sufficient interest for the readers of my journal.”
My experience with this process quickly revealed that most authors do not know how to write a list of contributions. The key feature of any contribution is that it should have a claim that can be verified by a knowledgeable reviewer. When the contributions did not meet this standard, I would return the paper and request a revision (sometimes I would just ask for a revision in email, that I would then forward to the AE). Often it would take two or three iterations for me to get a list of contributions that I felt I could then send through the review process.
Once I felt I had a valid list of contributions, I would make an initial assessment of whether the paper appeared to be publishable if all (or at least some of) the claims were true. I expected the AE to also look at the list of contributions and make the same assessment. The paper would then go to reviewers, with a request that part of their report would focus specifically on whether the claimed contributions were original and significant (that is, of publishable interest).
Finally, when the reviews are returned, the editors should first look at the reviewers’ assessment of the claimed contributions.
Side note: I include the “statement of contribution” paragraph in every one of my papers. Simply stunning how often the editors just ignore it.
Let referees be referees
With surprising frequency, referees would appoint themselves as authors, and they would decide how they think the paper should be written.
While referees should read the entire paper and feel free to make any comments that they feel would improve the paper, most important should be their assessment of the list of claimed contributions. Even if some contributions are not deemed original or significant, the reviewer may confirm one or more contributions that an editor feels are enough to justify publication. This assessment is key, and should be kept separate from other statements that a reviewer may make.
I often found reports that intermingled minor edits, fixable problems, and fundamental issues that are not fixable within the scope of the paper (a revision would really be a new paper).
Closing thoughts
This approach to reviewing puts the responsibility on authors to identify what is most important about their paper. This simplifies the review process by focusing the attention of editors and referees on what the author feels is most important. This should also help separate the fundamental decision of whether to accept a paper (including some form of revision) versus an outright rejection.
This approach reduces the tremendous amount of noise that currently exists in the review process. It helps reviewers organize their comments in a way that is most helpful to the editors, which is to separate the topics that are most relevant to accept or reject decisions, versus recommendations to authors that are primarily designed to improve the paper.
 different fields that work on sequential decision problems, but there is a price: it is an 1100 page book. xxxxxxxT
different fields that work on sequential decision problems, but there is a price: it is an 1100 page book. xxxxxxxT ideal for almost anyone who wants to first understand how to think about sequential decision problems. An introduction to the book is available at
ideal for almost anyone who wants to first understand how to think about sequential decision problems. An introduction to the book is available at
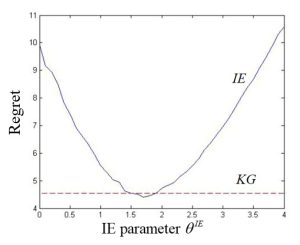 (known as interval estimation) in equation (1) above, to a more sophisticated policy called the knowledge gradient (see section 7.7.2 in
(known as interval estimation) in equation (1) above, to a more sophisticated policy called the knowledge gradient (see section 7.7.2 in 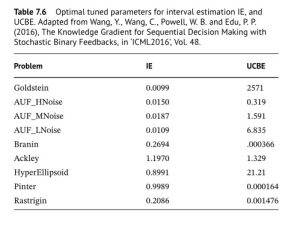 issue really boils down to scaling. The table to the right shows how two different policies for making decisions: The one under “IE” is given by equation (1)), while the one under “UCBE” uses a different term for capturing uncertainty. The table shows much more variation for the UCBE policy than the IE policy.
issue really boils down to scaling. The table to the right shows how two different policies for making decisions: The one under “IE” is given by equation (1)), while the one under “UCBE” uses a different term for capturing uncertainty. The table shows much more variation for the UCBE policy than the IE policy.