Warren B Powell
After a post on modeling sequential decision problems (aka RL problems), I was asked: “Are you using “x” for control/decision here? For RL or DP it is more common to use x/s for state, u for control, and r/c for reward/cost. Furthermore, what do these W variables mean?”
For many years, the RL community followed the notation of discrete Markov decision processes dating back to Bellman where “s” was state, “a” was a discrete action, 

But today, Dimitri Bertsekas’ books have received considerable attention in the RL literature. Dimitri uses classical notation from optimal control where x is the state, u is the control, and the state evolves according to the one-step transition function written using

where 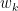
This is a mess, and it is time to fix this.
We have two books that have received considerable attention in the RL community (by Sutton and Barto’s Reinforcement Learning: An introduction and Bertsekas’ Dynamic Programming and Optimal Control: Approximate Dynamic Programming (4th edition), with completely conflicting notational systems, both of which have serious problems. Below I discuss how I have solved these problems in my new book, Reinforcement Learning and Stochastic Optimization: A unified framework for sequential decisions.
State variables:
“s” (in some form) is widely used as a state variable in dynamic programming which has been adopted throughout the CS/RL community. By contrast, “x” is the standard notation in the controls community. Not only is “s” (or 

There are many problems where the natural index is a counter (number of observations, arrivals, experiments, iterations, …). In that case, I use 



There is considerable confusion in the interpretation of state variables. The books on MDP/RL never define a state variable, while there are many books in the optimal control literature that provide explicit definitions. Click here for a more in-depth discussion of this rich topic.
Decision variables:
“x” has been used by the math programming community since the 1950s, and is standard notation around the world. While “a” is standard notation for dynamic programming, in the vast majority of applications it is discrete. By contrast, “x” may be binary, discrete, continuous scalar, as well as continuous or discrete vectors (in other words, anything). “x” was also adopted by the bandit community in computer science (which is closely associated with reinforcement learning), which means we have two communities, both in computer science and both associated with reinforcement learning, using two different notations for decision.
In my view, “x” is easily the most obvious choice for decision, which gives us a notational system that is welcoming to the field of math programming. This said, I do not feel there is any problem continuing to use “a” for discrete actions; not only is there a long history behind this notation (and I think this is important to respect), the idea of seeing “a” and then knowing that we are dealing with discrete actions has a certain appeal. If engineers still want to use “u” for continuous controls, I have no objection, but I encourage people new to the field to adopt “s” (or “S“) for state.
I have seen people object to x as a decision variable given its widespread use in machine learning. I do not feel there is a conflict here, since there are many problems where the input data to a machine learning problem is a decision (see, for example, the multiarmed bandit community). There are, of course, many settings in machine learning where we cannot control what we observe, just as there are settings where there is a mixture (I cannot control the attributes of a patient, but I can control what drug I prescribe, and the combination of attributes and drug influence how the patient responds).
Exogenous information
Fully sequential decision problems (decision, information, decision, information, ….) have to capture an exogenous information process that represent new information arriving to the system after a decision has been made.
In the MDP/RL modeling framework, this information is buried in the one-step transition matrix, which hides both the modeling of the exogenous information process (which is an important dimension of many problems) as well as how the system evolves over time.
The optimal control community has long used the notation
The reason why the “noise” variable 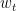
![[t, t+dt]](https://s0.wp.com/latex.php?latex=%5Bt%2C+t%2Bdt%5D&bg=ffffff&fg=000&s=0&c=20201002)


The transition function
The RL/MDP community likes to model transitions as a transition matrix 

where 
I have heard experts in RL tell me that they just “simulate the transition matrix.” No-one would ever compute a one-step transition matrix and then use it to draw samples of a transition (although this is possible). Any implementation of an RL algorithm uses a transition function rather than a transition matrix (or kernel).
Once you have the transition function and a model of the exogenous information process 
Objective function
The canonical model of a dynamic program in the MDL/RL community will list the reward 

The most common way to write an objective fun for dynamic programs (this is a specific version that I call the cumulative reward):

The objective is to find the best policy (at least, aspire to). This goal is completely missing from the standard MDP/RL model. Note that there are problems (in particular arising in offline settings such as laboratory experiments or simulators) where we might write our objective as

We would use this objective if we were optimizing the parameters of a simulator (see Chapter 7 of RLSO for a discussion of cumulative and final reward objectives, or Chapter 9, section 9.8 of RLSO for a more thorough discussion of objectives). We might even use a risk metric. Whatever choice we make, it has to be specified in our model!
Final remarks
My notation builds on the most important modeling styles from the Markov decision process, optimal control, math programming, machine learning and simulation communities. I think it is important for students new to the problem class to recognize that the study of sequential decision problems needs to stand on the shoulders of all of these fields. My new book RLSO is built on this notational framework.