Warren B. Powell Professor Emeritus, Princeton University Chief analytics officer, Optimal Dynamics
Within the vast class of problems that fall under the umbrella of sequential decisions (decision, information, decision, information, …) there are many problems that naturally call for policies that plan into the future in order to decide what to do now. Some examples are:- Deciding the next turn while planning a path to a destination over a road network.
- Planning which energy generators to have running tomorrow to meet energy demand given the uncertainty in wind, solar and temperature.
- Managing the flows of water between reservoirs given current forecasts of rainfall.
- Routing a fleet of vehicles making pickups and/or deliveries as orders arrive dynamically.
- Scheduling machines to meet order deadlines, with new orders arriving randomly.
- Managing the inventory of high value products to meet scheduled demand requests.
- People focusing on applications where you need to optimize problems (such as those above) over time in the presence of different forms of uncertainty, where you are particularly interested in using a deterministic lookahead policy (some call this “model predictive control”).
- Algorithmic specialists looking for a nice challenge. In particular, parametric CFAs represent the bridge between machine learning and stochastic programming. While a parametric CFA is easy to implement, there are difficult algorithmic challenges that parallel problems such as fitting neural networks to large datasets.
The challenge of planning under uncertainty
All of these problems require planning into the future to determine what decision to make now. Given the different forms of uncertainty (travel times, customer demands, rainfall, product yields, prices, performance of vaccines, …), we should be capturing this uncertainty as we plan if we want to make the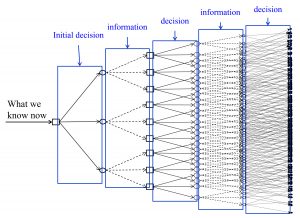 best decision now. The problem is that planning under uncertainty is hard.
The figure to the right illustrates the familiar explosion of a decision tree, and this is for a very simple problem (e.g. three possible decisions each time period). Bellman’s introduction of Markov decision processes was a breakthrough for these problems, but this has been restricted to small (even toy) problems because of the infamous “curse of dimensionality” (there are actually three curses).
Now imagine we are managing a fleet of 1000 vehicles where we may have a decision vector with 10,000 dimensions. In the 1950s, George Dantzig introduced the idea of using a lookahead policy where the uncertainties in the future are represented through a small sample (his motivating application was in scheduling airlines). This idea created the field of stochastic programming, which has produced thousands of papers and a number of books. If we let
best decision now. The problem is that planning under uncertainty is hard.
The figure to the right illustrates the familiar explosion of a decision tree, and this is for a very simple problem (e.g. three possible decisions each time period). Bellman’s introduction of Markov decision processes was a breakthrough for these problems, but this has been restricted to small (even toy) problems because of the infamous “curse of dimensionality” (there are actually three curses).
Now imagine we are managing a fleet of 1000 vehicles where we may have a decision vector with 10,000 dimensions. In the 1950s, George Dantzig introduced the idea of using a lookahead policy where the uncertainties in the future are represented through a small sample (his motivating application was in scheduling airlines). This idea created the field of stochastic programming, which has produced thousands of papers and a number of books. If we let 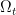 represent a sample of outcomes (demands, deviations from wind forecasts, travel times, equipment failures), then we could make a decision using
represent a sample of outcomes (demands, deviations from wind forecasts, travel times, equipment failures), then we could make a decision using
 (1)
subject to some constraints for the decision to be made now,
(1)
subject to some constraints for the decision to be made now,  , as well as the decisions that would be made in the future
, as well as the decisions that would be made in the future  for each scenario
for each scenario  .
This optimization problem is much larger than a method that just uses point estimates of the future, as is done with navigation systems that use a point estimate of travel times over each link in a network. There are many problems where some or all of the variables have to be integer; introducing scenarios in the lookahead model can make these problems exceptionally difficult.
What is often overlooked is that even when we can solve a stochastic program within computational constraints (a major issue in many applications), an optimal solution to a stochastic program is not an optimal policy, because a number of approximations have been made in the lookahead model. Some of the most significant include:
.
This optimization problem is much larger than a method that just uses point estimates of the future, as is done with navigation systems that use a point estimate of travel times over each link in a network. There are many problems where some or all of the variables have to be integer; introducing scenarios in the lookahead model can make these problems exceptionally difficult.
What is often overlooked is that even when we can solve a stochastic program within computational constraints (a major issue in many applications), an optimal solution to a stochastic program is not an optimal policy, because a number of approximations have been made in the lookahead model. Some of the most significant include:
- The replacement of a fully sequential decision problem in the future. Ideally, we want to make decision
, observe information
, make another decision
, observe information
(and so on). With the two-stage approximation used in the stochastic program above, we assume we first observe all the information
and then make all the decisions
. This means
, which means decisions starting at time
- Replacing all outcomes with a sample.
- Stochastic outcomes in the future have to be independent of any decisions (at time t or later).
- Limiting the horizon
with the truncated horizon
.
- Often other approximations are made in the future, such as discretizing time periods (say, into hours instead of minutes, or days instead of hours).
- The stochastic program is complicated!
- It is hard to solve, requiring computation times that may be far beyond what can be tolerated in practice.
- The analyst has very little control over how the resulting policy responds to uncertainty, while in practice, practitioners often have very good intuition about how they want to deal with uncertainty.
The parametric cost function approximation
The most common approach used in practice is to solve a deterministic model, but introduce parameters to improve robustness of the solution. Examples include:- We may use the shortest path from the deterministic model, but we leave
minutes earlier than the deterministic model recommends so we arrive on time.
- We plan our energy generator for tomorrow, but introduce a vector
of reserves in different regions of the network, taking known bottlenecks in the grid into account.
- We plan the flow of water between reservoirs, but introduce upper and lower limits, captured by a vector
- Scheduling vehicles or machines to perform tasks, but introducing slack
has been a widely used engineering heuristic, which has been largely dismissed by the academic community as nothing more than a deterministic approximation. Many who work in stochastic programming assume that introducing scenarios automatically means that these models are better, but these claims are made with virtually no empirical evidence (and certainly no theoretical support, given the approximations required by stochastic programming).
Tunable parameters can be introduced as adjustments to the objective function, or (more often) as changes to constraints. We can write this in a generic way as
 (2)
subject to
(2)
subject to
 We can parameterize the objective function, and/or the constraints. For an illustration, see “A Case Application” below where I show an LP with a parameterized set of constraints.
The central idea here is to parameterize a (typically deterministic) optimization model, which creates two challenges:
We can parameterize the objective function, and/or the constraints. For an illustration, see “A Case Application” below where I show an LP with a parameterized set of constraints.
The central idea here is to parameterize a (typically deterministic) optimization model, which creates two challenges:
- How do we parameterize the optimization model? This work belongs in the context of the motivating application, since it draws on insights into the structure of the particular application. The issues are comparable to the design of any parametric model in statistics, but (we believe) the opportunities are much richer.
- Tuning the policy
– This is a purely algorithmic exercise which offers a number of fresh challenges in context of parameterized optimization problems, just as neural networks have introduced fresh challenges for parameter search while fitting neural networks to datasets.
Designing the parameterization
As with any parametric model, the structure of the parameterization is more art than science (as of this writing). Parametric models date back to the early 1900s in the statistics community. Easily the most popular form of parametric model is a model that is linear in the parameters, which we might write as where
where  is a set of features (also known as “basis functions”) that depend on an input dataset x. We could use this idea to modify our objective function, giving us
is a set of features (also known as “basis functions”) that depend on an input dataset x. We could use this idea to modify our objective function, giving us
 Here, the additional term
Here, the additional term  could be called a “cost function correction term,” and requires carefully chosen features
could be called a “cost function correction term,” and requires carefully chosen features  .
The most common way to parameterize constraints would be through the linear modification of the right hand side, which we can write as
.
The most common way to parameterize constraints would be through the linear modification of the right hand side, which we can write as
 where
where  is the elementwise product of the vector
is the elementwise product of the vector  times the similarly dimensioned vector
times the similarly dimensioned vector  , and
, and 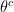 is a set of additive shifts.
Adding schedule slack would require parameterizing the
is a set of additive shifts.
Adding schedule slack would require parameterizing the 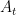 matrix. We can also shift upper and lower bounds on .
matrix. We can also shift upper and lower bounds on .
Tuning the parameterization
However you design the modified objective function, we then face the problem of tuning. This is its own optimization problem, which we might write as
 (3)
where the evolution of the state variable is determined by
(3)
where the evolution of the state variable is determined by
 and given by an underlying stochastic model for generating the sequence
and given by an underlying stochastic model for generating the sequence
 We refer to this as the stochastic base model, which is typically implemented as a simulator, but there are settings where we are optimizing the policy in the field.
The first question we have to answer is: how are we going to evaluate the policy? We are going to need to run a simulation, but there are two ways to do this:
We refer to this as the stochastic base model, which is typically implemented as a simulator, but there are settings where we are optimizing the policy in the field.
The first question we have to answer is: how are we going to evaluate the policy? We are going to need to run a simulation, but there are two ways to do this:
- Simulating the policy in the computer. Here, there are two ways of generating the exogenous information process
:
-
- Sampling from a stochastic model
- Using sequence of observations from history (often called backtesting).
-
- Testing in the field – This can be very slow (it takes a day to simulate a day), but it avoids any of the modeling approximations of Monte Carlo simulation. Typically this means that we have to learn by doing, which means that we have to live with our outcomes (this is called optimizing cumulative reward).
- Derivative-based stochastic search – See chapter 5 of Reinforcement Learning and Stochastic Optimization.
- Derivative-free stochastic search – See chapter 7 of Reinforcement Learning and Stochastic Optimization.
 is central to the parametric CFA policy, just as an objective function is central to the design of any search algorithm in deterministic optimization.
An important property of a parametric CFA is that it will typically be the case that the coefficient vector is inherently scaled. At the bottom of this page, we present a case study where the parameter vector is centered around
is central to the parametric CFA policy, just as an objective function is central to the design of any search algorithm in deterministic optimization.
An important property of a parametric CFA is that it will typically be the case that the coefficient vector is inherently scaled. At the bottom of this page, we present a case study where the parameter vector is centered around 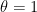 . It uses rolling forecasts, and if the forecasts happen to be perfect, then the optimal value of satisfies . This would not be the case if we were using, for example, a linear model or neural network.
. It uses rolling forecasts, and if the forecasts happen to be perfect, then the optimal value of satisfies . This would not be the case if we were using, for example, a linear model or neural network.
From stochastic lookaheads to stochastic base models
It is very common in the algorithmic community to view a stochastic lookahead as the gold standard. The problem is that stochastic lookaheads are inherently complicated, as hinted by the exploding scenario tree above. The stochastic programming community has learned to live with the different approximations this approach requires. For example, there may be arguments about how many scenarios are required, but rarely is there a debate about the use of two-stage approximations, since three-stage models are almost always unsolvable. They do not even raise the possibility of modeling every time period in the future as its own stage.
The process of tuning the parametric CFA, on the other hand, focuses on putting the stochastic model in the simulator required to evaluate . While putting complex dynamics in a lookahead model is quite difficult, it is comparatively easier in the simulator captured by the transition function . This means that the tuned value of has these complex dynamics captured by the optimal solution 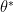 .
For this reason, we claim:
A properly designed and tuned parametric CFA may easily outperform a much more complex stochastic lookahead, such as those produced by stochastic programming.
It is important to emphasize that no policy, including parametric CFAs, is a panacea. The universe of sequential decision problems is simply too vast. However, the types of problems that are good candidates for stochastic programming (regardless of whether you are using scenario trees or SDDP) are likely to be good candidates for parametric CFAs.
There are many papers that formulate stochastic programs to solve a sequential decision problem, which do not then run simulations, but there are some that do. The most common competition is to compare a stochastic lookahead (using scenario trees) against a “deterministic model.” These comparisons never compare against a properly parameterized and tuned deterministic model.
.
For this reason, we claim:
A properly designed and tuned parametric CFA may easily outperform a much more complex stochastic lookahead, such as those produced by stochastic programming.
It is important to emphasize that no policy, including parametric CFAs, is a panacea. The universe of sequential decision problems is simply too vast. However, the types of problems that are good candidates for stochastic programming (regardless of whether you are using scenario trees or SDDP) are likely to be good candidates for parametric CFAs.
There are many papers that formulate stochastic programs to solve a sequential decision problem, which do not then run simulations, but there are some that do. The most common competition is to compare a stochastic lookahead (using scenario trees) against a “deterministic model.” These comparisons never compare against a properly parameterized and tuned deterministic model.
A case application
We have demonstrated this idea in a complex form of energy storage application. The energy system consists of four elements: energy from the grid, energy from a wind farm, a storage device, and a load (demand) for energy: There is a demand for energy that follows a consistent hour-of-day pattern (figure below on the left), along with rolling forecasts of wind that are updated hourly (figure on the right).
There is a demand for energy that follows a consistent hour-of-day pattern (figure below on the left), along with rolling forecasts of wind that are updated hourly (figure on the right).
 These two types of variability are different in an important way. The time-of-day demand pattern means that the high and low points occur consistently at the same time of day, which could be picked up with a parameterized policy where the parameter
These two types of variability are different in an important way. The time-of-day demand pattern means that the high and low points occur consistently at the same time of day, which could be picked up with a parameterized policy where the parameter  is indexed by time.
This is not the case with the rolling forecast, where the peak wind forecast can change over time, as it does in the illustration of forecasts in the figure on the right. In this figure, black is the actual wind (observed at the end of the day), while the other lines are forecasts made each hour, where the peak wind changed over the course of the day. If
is indexed by time.
This is not the case with the rolling forecast, where the peak wind forecast can change over time, as it does in the illustration of forecasts in the figure on the right. In this figure, black is the actual wind (observed at the end of the day), while the other lines are forecasts made each hour, where the peak wind changed over the course of the day. If  is the forecast of wind for hour
is the forecast of wind for hour  made as of hour
made as of hour  , then the vector of forecasts
, then the vector of forecasts  has to be treated as part of the state variable. See here (section 5) for a proper model of rolling forecasts for this energy storage problem.
[One way to solve this problem using a stochastic lookahead model would be to make the forecast a latent variable, which means we model the errors in the forecast, but otherwise lock the forecasts in place and treat them as constants (this means we are not modeling the fact that these forecasts are evolving over time). Imagine that we solve this stochastic model using approximate dynamic programming, which means that we have to estimate value function approximations
has to be treated as part of the state variable. See here (section 5) for a proper model of rolling forecasts for this energy storage problem.
[One way to solve this problem using a stochastic lookahead model would be to make the forecast a latent variable, which means we model the errors in the forecast, but otherwise lock the forecasts in place and treat them as constants (this means we are not modeling the fact that these forecasts are evolving over time). Imagine that we solve this stochastic model using approximate dynamic programming, which means that we have to estimate value function approximations  where
where  might capture how much energy is stored in the battery, but does not include the current set of forecasts
might capture how much energy is stored in the battery, but does not include the current set of forecasts  . This means that when we step from t to t+1, we would have to re-estimate the value functions entirely from scratch.]
A powerful way to handle both the time-of-day effect, as well as the rolling forecast, is to use a deterministic lookahead model, parameterized by introducing coefficients
. This means that when we step from t to t+1, we would have to re-estimate the value functions entirely from scratch.]
A powerful way to handle both the time-of-day effect, as well as the rolling forecast, is to use a deterministic lookahead model, parameterized by introducing coefficients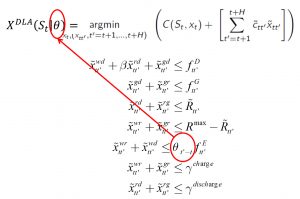
 for
for  in front of each forecast
in front of each forecast  . The resulting policy is a simple linear program given by the figure to the right. This policy is no more complicated than a simple deterministic lookahead, obtained by setting
. The resulting policy is a simple linear program given by the figure to the right. This policy is no more complicated than a simple deterministic lookahead, obtained by setting  for all
for all  .
This lookahead policy is both stationary, and has the current forecast imbedded in the policy. Of course this means that we have to re-optimize the deterministic lookahead as the forecasts change, but this is extremely fast (a fraction of a second).
Using this policy in the field is very easy. Tuning the parameter vector , however, is not. We used a stochastic gradient algorithm based on Spall’s simultaneous perturbation stochastic approximation (SPSA) method, which allows us to estimate an entire gradient with just two function evaluations. However, our simulations were extremely noisy, which meant that we had to perform “mini-batches” of perhaps 20 simulations which were then averaged. Also, the objective function is nonconvex, but appears to be unimodular. Please click here for a paper summarizing our work on tuning the policy, which produced results 30 to 50 percent better than a basic lookahead with
.
This lookahead policy is both stationary, and has the current forecast imbedded in the policy. Of course this means that we have to re-optimize the deterministic lookahead as the forecasts change, but this is extremely fast (a fraction of a second).
Using this policy in the field is very easy. Tuning the parameter vector , however, is not. We used a stochastic gradient algorithm based on Spall’s simultaneous perturbation stochastic approximation (SPSA) method, which allows us to estimate an entire gradient with just two function evaluations. However, our simulations were extremely noisy, which meant that we had to perform “mini-batches” of perhaps 20 simulations which were then averaged. Also, the objective function is nonconvex, but appears to be unimodular. Please click here for a paper summarizing our work on tuning the policy, which produced results 30 to 50 percent better than a basic lookahead with  . As we said at the beginning, there is a lot to do here for people who enjoy algorithmic research.
We note that this approach guarantees that we will do at least as well, if not better, than a standard deterministic lookahead (that is, with ). Most important is that it is no more complicated to solve than a standard deterministic lookahead. The additional work is in the tuning of the parameters which is done in the lab, but this requires building a simulator. It is possible to envision an approach that uses self-tuning in the field, drawing on the tools of derivative-free stochastic search.
This application nicely illustrates how parameterizing, say, a deterministic lookahead helps to perform valuable scaling. If our forecasts were perfect, then we will find that
. As we said at the beginning, there is a lot to do here for people who enjoy algorithmic research.
We note that this approach guarantees that we will do at least as well, if not better, than a standard deterministic lookahead (that is, with ). Most important is that it is no more complicated to solve than a standard deterministic lookahead. The additional work is in the tuning of the parameters which is done in the lab, but this requires building a simulator. It is possible to envision an approach that uses self-tuning in the field, drawing on the tools of derivative-free stochastic search.
This application nicely illustrates how parameterizing, say, a deterministic lookahead helps to perform valuable scaling. If our forecasts were perfect, then we will find that  . With large errors, we found that the best values of ranged between 0 and 2. This behavior dramatically simplified the search.
. With large errors, we found that the best values of ranged between 0 and 2. This behavior dramatically simplified the search.